
In this article, we’ll be covering the foundational principles of localisation in React. We’ll start by looking at what localisation is and why it’s important before jumping into code samples to prepare your app for a global audience.
According to a study done by the European Commission, only 53% of internet users would use a website in English if their native language wasn’t available, and over 44% felt as if they might be missing information or receiving inaccurate information because a website wasn’t in their native language. Above all, 72% of participants reported they spend “most” or “all” of their internet time on websites that offer their native language, and even those with high proficiency in English spend 60% more time browsing in their own language.
It’s clear that making users feel comfortable with your product is important, especially when it comes to being inclusive of their language and cultural needs. The goal of localisation is to do exactly that. With a good infrastructure in place, you can easily set your product up for success on a global scale and ensure your users are getting the experience that’s right for them.
What is localisation?

In software development, localisation is the process of adapting a product to meet your users’ language and cultural requirements. It’s often shortened to l10n, as there are ten letters between the l and n. This includes formatting numeric values (such as date, time, and currency), imagery (such as icons, symbols, and colours), and translating text. As a rule of thumb, everything that your users see is fair game to be localised.
You’ll often see the term internationalisation (shortened to intl or i18n) thrown around when localisation is mentioned. These concepts both share the same goal, but internationalisation is a broader term that describes the overall process of creating a product that can be shipped on a global scale. It focuses on the infrastructure and architecture of a product, whereas localisation dives deeper into the details of what needs to be accomplished before a product can be considered “ready” for a global user base.
Internationalisation does, however, significantly affect the ease of a product’s localisation. Retrofitting a linguistically- and culturally-centered set of features for a global user base is much more difficult and time-consuming than designing a feature with the intent of shipping it globally from the very beginning. Think back to the Y2K problem — hundreds of thousands of computer systems worldwide relied on two-digit year fields, rather than four. When the turn of the century hit, systems reported the year as 1900 rather than 2000, leading to many serious real-world issues. If these systems had been built with this scenario in mind, the transition would have been much smoother for everyone involved.
Similarly, even if you don’t think you’ll be shipping globally now (and maybe not even for a long time), it can still be useful to build with internationalisation in mind. Some of the techniques we’ll cover are generally good practices in any software development. The overarching goal of both localisation and internationalisation is to remove barriers for a global product, including bidirectional text support, Unicode support, and support for dynamic UI, minimising hardcoded strings and string concatenation.
Why is localisation important?
Besides providing us with a method for handling strings in a structured way, localisation is important for three major reasons.
First, while it can cost a lot of development time to set up the infrastructure and money on professional translations, localising your product expands your user base and therefore your income stream. Only 25.2% of internet users worldwide speak English, and 76.3% of all internet users are spread out across ten languages.
Second, it’s important to be sensitive across all cultures. During my time at Microsoft, a bug report was filed titled “VS Installer welcome image contains offensive element for Chinese [users]”. This was a huge problem for our Chinese market, and a fix was released to production within ten days.
Finally, in the context of web apps, localisation allows us the opportunity to provide in-context translations that focus on quality and experience, rather than automatic translations provided by browsers.
Localisation goals
When we think about how to implement a localisation solution in our app, it’s important to lay out a few goals to help guide us.
Single source of truth
There should be no confusion about which version of an English string is the correct one. This helps eliminate inconsistencies across the product (for example: we shouldn’t have some features that say “Remove” and others that say “Delete” when they perform the same action).
Arbitrary number of languages
There should be no upper bound to how many languages we’re able to support. Adding support for a new language to the product should require minimal effort from developers.
Decoupled
Adding translations and developing features should be kept as independently as possible, so that both tasks can happen in parallel and without conflicts.
Automated
We should strive to automate as much of this process as possible to make our solution more efficient and less error-prone.
Watch Isabela’s Nordic.js talk on localisation:
Localisation in React
One library you may have come across for localisation in React is react-intl. This is a fine solution for very simple React apps, but it doesn’t support vanilla JavaScript or other frameworks (as the name implies).
A side effect of this restriction is that, even if you’re working within a React app, a scenario where you have a generic .js or .ts file that needs to handle text (and therefore localisation) isn’t supported. Additionally, this library also requires that the React component using it be wrapped by a Higher Order Component. This breaks our decoupling goal because now when we’re developing features, we need to keep in mind that they must be HOC-wrapped and limits our tech stack to React. So what’s the alternative?
The best alternative I’ve found is react-universal-intl. Despite its name, it can handle all your localisation needs for any JavaScript app, including vanilla JS. The basic approach is that you define a JSON file with all the supported locales and the string resources used in your app. Then in the .js or .ts file, you call intl.get() with the key for your string resource.
This solution is nice because your strings are separated from your app, and you don’t have hardcoded values anymore. We’re not done with the localisation yet since we’re only pulling English values in our JSON file, but we have a strong architecture in place to support it. This is also a great approach for strings in general, since they’re isolated to a single JSON file, to ensure consistency across your product.
Using react-intl-universal
In order for localisation to work, a message has to be written and translated as a single unit. For strings with proper nouns and names, or numerical values that need to appear within a phrase, passing in a variable like we did in the example above is a fine approach.
Besides that, however, you should never concatenate your own strings from various formatted elements and your own injected variables. Not only does this make it extremely hard for translators to understand the full meaning of your message, but these translated strings could end up with the wrong grammar. This is most commonly seen in languages that differentiate between masculine and feminine words. If you rely on passing in a data type as a variable to your translation, you might end up with incorrect pronouns.
For example, in Portuguese, the word “message” is feminine, so the feminine form of “new” should be used to describe it. The correct translation for the phrase “New message” then is “Nova mensagem” and not “Novo mensagem”. However, the word “email” (adopted directly from English) is considered masculine, so the masculine of “new” should be used. The correct translation for “New email” then is “Novo email”. If these had been translated as a single string with variables passed in for the different supported data types (eg message, email and activity), you would have ended up with the wrong form of the word “new” in at least one instance, depending on if you hardcoded “novo” or “nova” in your JSON file.
This is where the ICU MessageFormat comes into play. It provides a programming language agnostic format for translating strings and is enforced by the react-universal-intl library. The ICU MessageFormat requires the following structure: { name, type, format }.
name is the key in the locale JSON file, type is the set of variables or data types (such as number, data, time, or plural), and format is optional and provides additional context for how the value should be displayed.
Pluralisation: You can pass variables to the library call and corresponding numerical values to determine what string you want for each variant.
Dates: You can pass in a Date object and a format type to choose how to display the date. This format can be either short, medium, long, or full and defaults to short if not provided.
Times: Similar to dates, timestamps from Date objects can be localised and formatted.
Currency: As we covered earlier, currency also needs to be localised. This is done similarly to dates and times, with the format parameter representing the ISO standards country code.
The formatting for dates, times, and currency can also be dynamically detected once the library is initialised, so you can use the default formatting for the user’s region.
Implementing localisation in React
In order to make localisation low-friction for end users, we should automatically recognise the user’s default locale. To round out the experience, we should also allow the user to change this from a settings page. Finally, we should leverage the common locale data mentioned above for formatting numerical values whenever possible.
The first thing needed is the setup of determining the user’s current locale when the app loads. Most of this article will be in React for simplicity, but since react-universal-intl is also compatible with vanilla JS, the examples shown should work with minor tweaks. We also define an array of dropdown objects, SUPPORTED_LANGUAGES, that can be used by a settings page to allow users to set their preferred locale.
As you can see in the code above, we can use the user’s preferred locale if it exists in our state (perhaps stored in Redux). Otherwise, we can determine their locale by checking the URL or cookies for a lang token. If none of these options exist or are not supported by the app (as defined by SUPPORTED_LANGUAGES), it’s reasonable to default to English (or whatever language you choose depending on your main audience). I also highly suggest using the json-loader npm package to dynamically require your locale JSON files. This will prevent your app from importing unnecessary locale data files.
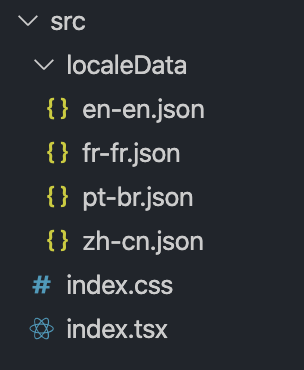
The overall file structure of your app should resemble the above image. Each locale has its own JSON file of translated strings, which all live in a localeData directory. This helps keep the string file isolated from the rest of the code and allows developers to see which languages are supported at a quick glance.
Finally, hooking up the dropdown for the user’s preferred locale can update the Redux state, or perhaps change the URL parameter used by intl.determineLocale() to update the localisation strategy (location.search = `?lang={e.target.value}`).
As localisation also includes symbols and images, we can use the currentLocale from the library to determine what elements to render as well.
Testing localisation
We’ve covered a lot about how we’d localise strings across our product, but an important aspect of doing so is testing that we haven’t missed any strings. You may be thinking that you only know one language or don’t want to rely on faking a locale or toggling user settings to manually test strings across the product.
To solve this, we can use a strategy called pseudo-localisation. By leveraging this, we can force our development environment to use a specific locale file that returns Unicode text that closely matches English, but looks obviously different with various accent marks and ligatures. We used this technique a lot when I worked at Microsoft. This is a screenshot of what a development build of Xbox looks like with pseudo-localisation enabled.
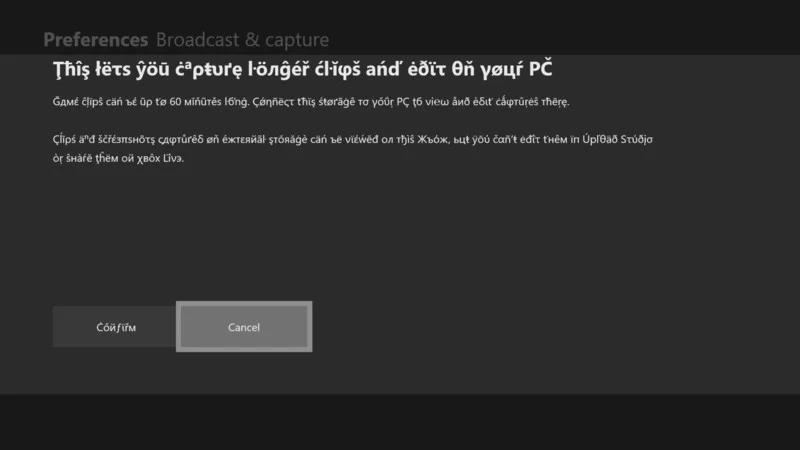
As you can see from this screenshot, the text is still legible but makes it very apparent what strings are still hard coded and aren’t being sent through the localisation service. In this case, we can see that the “Cancel” button doesn’t show up in the Unicode font, so we know it hasn’t been translated.
My preferred method of setting up pseudo-localisation for projects is with CLI tools that generate the pseudo-localised JSON files. These files can then be used in place of the locale JSON files in local development builds. I like the pseudo-localization npm package. Once installed (npm install pseudo-localization), you can use the CLI version to generate the JSON file by running npx pseudo-localization ./path/to/locales/en.json -o ./path/to/locales/pseudo.json. From there, we can do something like this in our app code:
If the process environment is development, we can immediately require the pseudo.json file. Otherwise, we’ll require whatever locale was detected. The only thing you need to remember to do (or automate!) is to re-run the pseudo-localisation CLI tool whenever you create or edit a string in your base locale JSON file. Otherwise, an empty string will be rendered if it doesn’t exist in the pseudo.json file.
We should also update our unit and integration tests to make sure they catch any non-localised strings and make our tests independent of what locale they’re run under. This is pretty straightforward to do. You can write your test like normal but, instead of expecting the text to equal a hard coded string, you can expect it to equal a value returned by the intl library.
Wrapping up
To wrap things up, you should avoid hard coded strings in your product. Even if you don’t think you’ll be localising in the near future (or ever!), it’s useful to have all your strings in one JSON file, and it can be beneficial to have an architecture in place that can easily support localisation.
You should also translate messages as single units, minimise non-numerical string variables, and avoid manual string concatenation. It’s important to think about localisation at a high level and not focus only on the translation of strings. Dates, currencies, and time formats should all be taken into account. It’s also crucial to avoid direct translations if possible (for example, using automatic translation services), as they usually result in very literal string translations that don’t take into account the context and function of a particular string. Overall, I’d suggest using the react-intl-universal and pseudo-localization libraries and avoiding DIY localisation strategies.
The most important thing to keep in mind when considering localisation is that you’re building a product for your users. It’s your responsibility to give them a positive experience through inclusive design, and this includes minimising language and cultural barriers. By localising your product, you can not only ensure this, but also expand your user base to the over 75% of users who aren’t native English speakers.